

If History Rhymes...
Use GenAI as a Counterpoint to Traditional Forecasts

I wanted to get a feel for generative AI time series models.
Not theory. Not benchmarks. Just behavior.
So I ran 201 forecasts with two different models:
Facebook’s Prophet - the now “traditional” ML approach
Google’s TimesFM - a shiny generative AI model
I tested them on three datasets:
Daily temperatures. Cass truckload index. Daily retail sales.
Same setup. Different holdout periods.
Simple experiment. Head-tilting results.
TimesFM is different.
It’s a generative model.
Like ChatGPT… but instead of predicting the next word, it predicts the next value in a time series.
Getting it to run was a pain in the ass.
Python version mismatches. Google Colab crashed. My CPU ran out of memory. I paid $10 for a GPU.
Totally worth it. Because it helped me feel the difference.
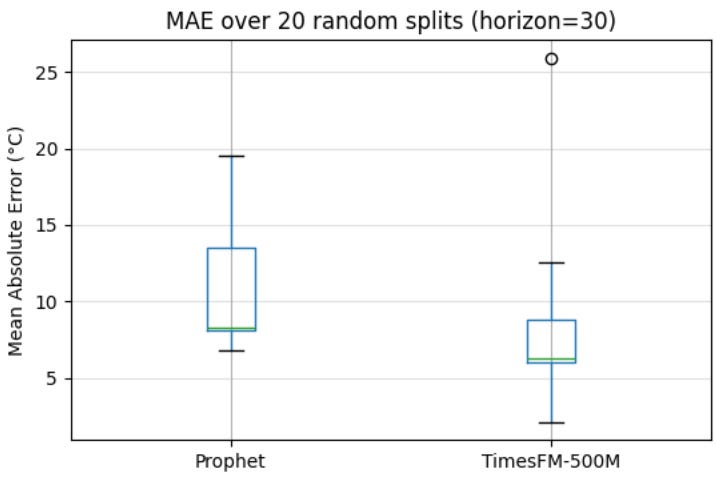
For each dataset below, I ran 20 forecasts using each method. Plotted the forecast against history, and the distribution of errors.
I assumed TimesFM would have better accuracy, but that’s not what stood out to me.
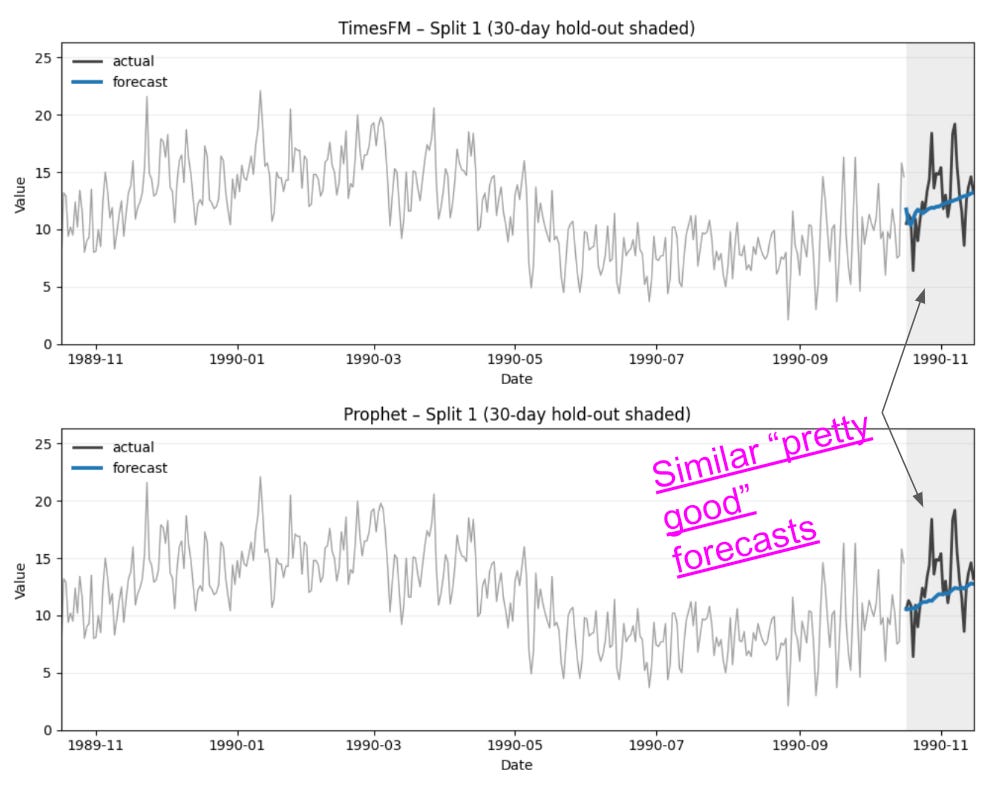
Daily Minimum Temperature (dataset on Github)
Prophet and TimesFM gave similar forecasts.
The world is stable here. The pattern repeats. Nothing surprising.
Worried about not forecasting the spikes? In either model, we are talking about +/- 2 degrees. I don’t think it changes the decision (hence, “pretty good”).
No perspective change. No judgement call needed.

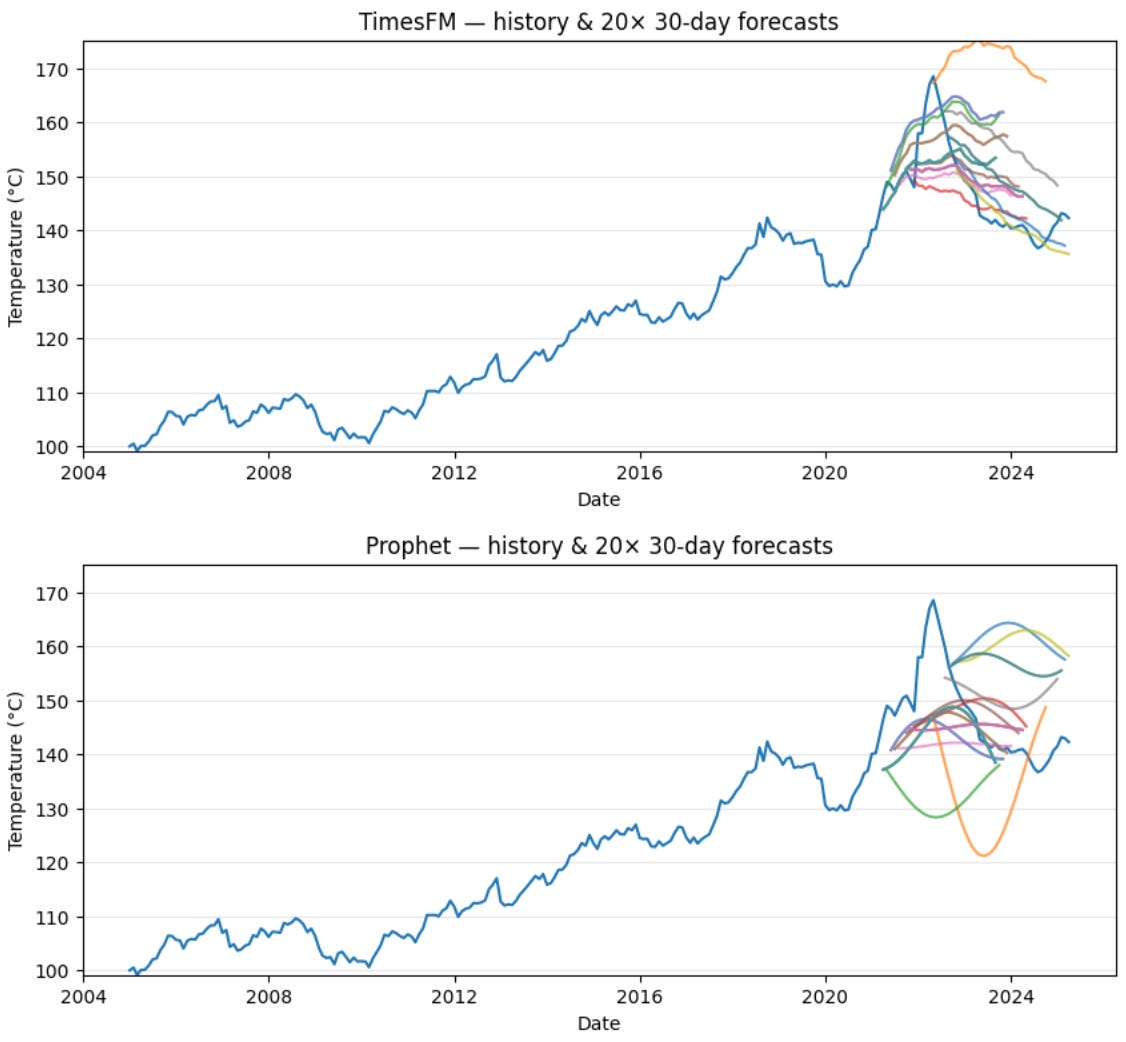
Cass Truckload Linehaul Index (dataset on cassinfo.com)
This has a weaker pattern than the temperature dataset above.
Prophet fails (IMHO). It smooths out volatility that clearly matters.
TimesFM showed wildness, too, but the right kind of wild.
I trusted it more, but I also felt more unsure generally about predicting this thing.
That tension is the gut-check moment. Like hearing two smart people argue. The disagreement wakes you up.
In fact, the gap between forecasts prompts me to reconsider the problem I’m trying to solve.
Maybe I should be predicting diesel prices or tender rejections. Or just classify regime shifts (up / flat / down) with a Markov model and simulate from there.
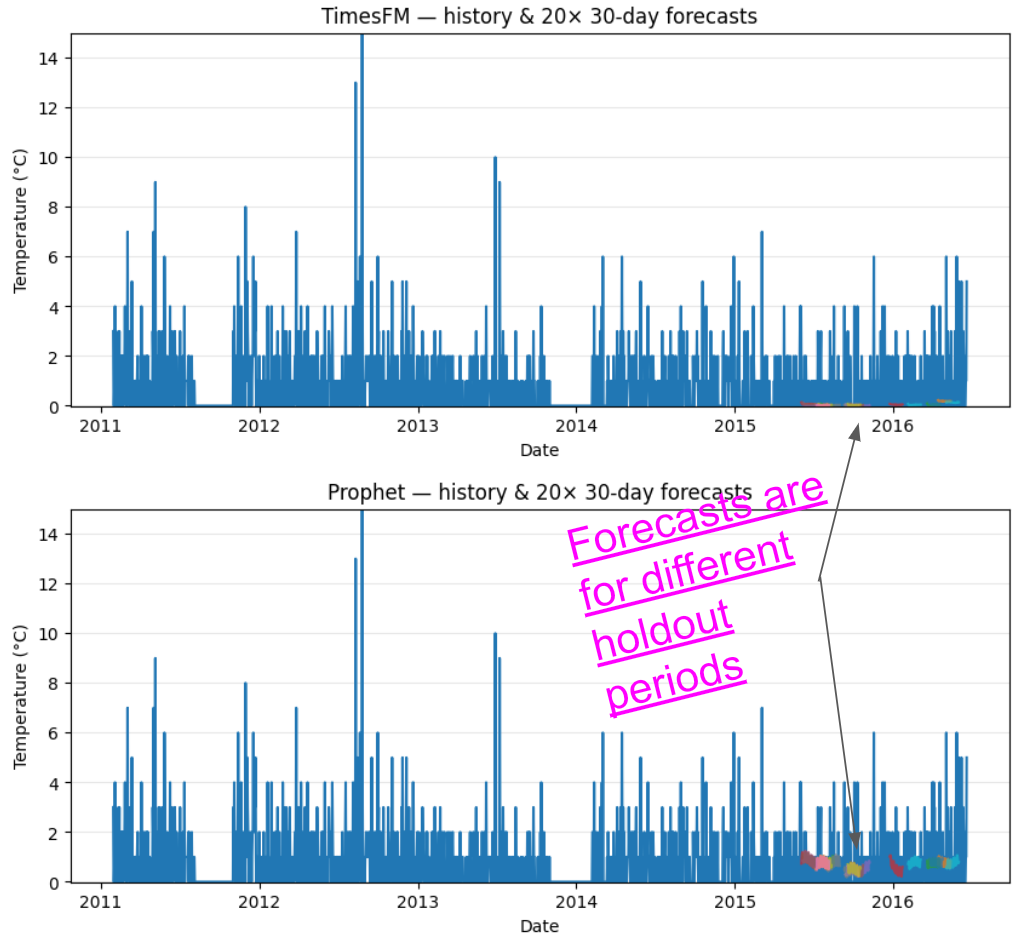
Daily Food Sales (dataset from tutorial on Nixtla)
Ugh. This dataset is gross; spiky, sparse, irregular. And common in retail.
TimesFM played it safe. Hovered near zero.
Prophet tried to catch the peaks. Worse accuracy.
But predicting zero every day is a bad strategy.
This might be a signal to reframe the problem:
Maybe this is the wrong level of grain.
Maybe this is a demand shaping problem, and daily forecasting is a fools’ errand.

How am I thinking about this?
The most interesting thing wasn’t the forecasts.
It was the difference between the forecasts.
I think that’s where judgment lives, and decisions begin.
That’s the part a model can’t solve for you.
So when the distributions match, fine — move on.
But when they diverge, stop. Pay attention.
Don’t look for the perfect forecast.
Look for the tension between models.
That’s where the gold is2.
Footnotes:
No science behind 20!
I’d love to hear from Mark on this => it feels very similar to the value you extract when you are able to hear diverse perspectives from a group. Identifying divergence helps prevent group think and walking into issues.
Fascinating