
Oops. Bad context.
Someone could make a good-context service for AI Agents

Last week I was sick. I asked Claude: do I suck?
“Of course not, Frank.” It listed family, writing, running, work accomplishments. Then: “plus, you now have this great relationship with Alex.”
…
Alex and I parted ways months ago. Oops. Bad context.
AIs need good context to make good decisions.
So we give them a lot of information as a proxy for context. If I want my AI to make better decisions about inventory, I upload research papers about inventory optimization1.
Yes, better decisions. But also more tokens (i.e. more cost).
That’s just the way it is. But I wondered; if I could give my AI the fundamentals of those research papers instead of the full thing, could I get better decisions at lower cost. So I set up an experiment…2
I started with a random paper from SSRN; Inventory Competition & the Cost of a Stockout.

And from this paper I had Claude3 extract any causal statements.
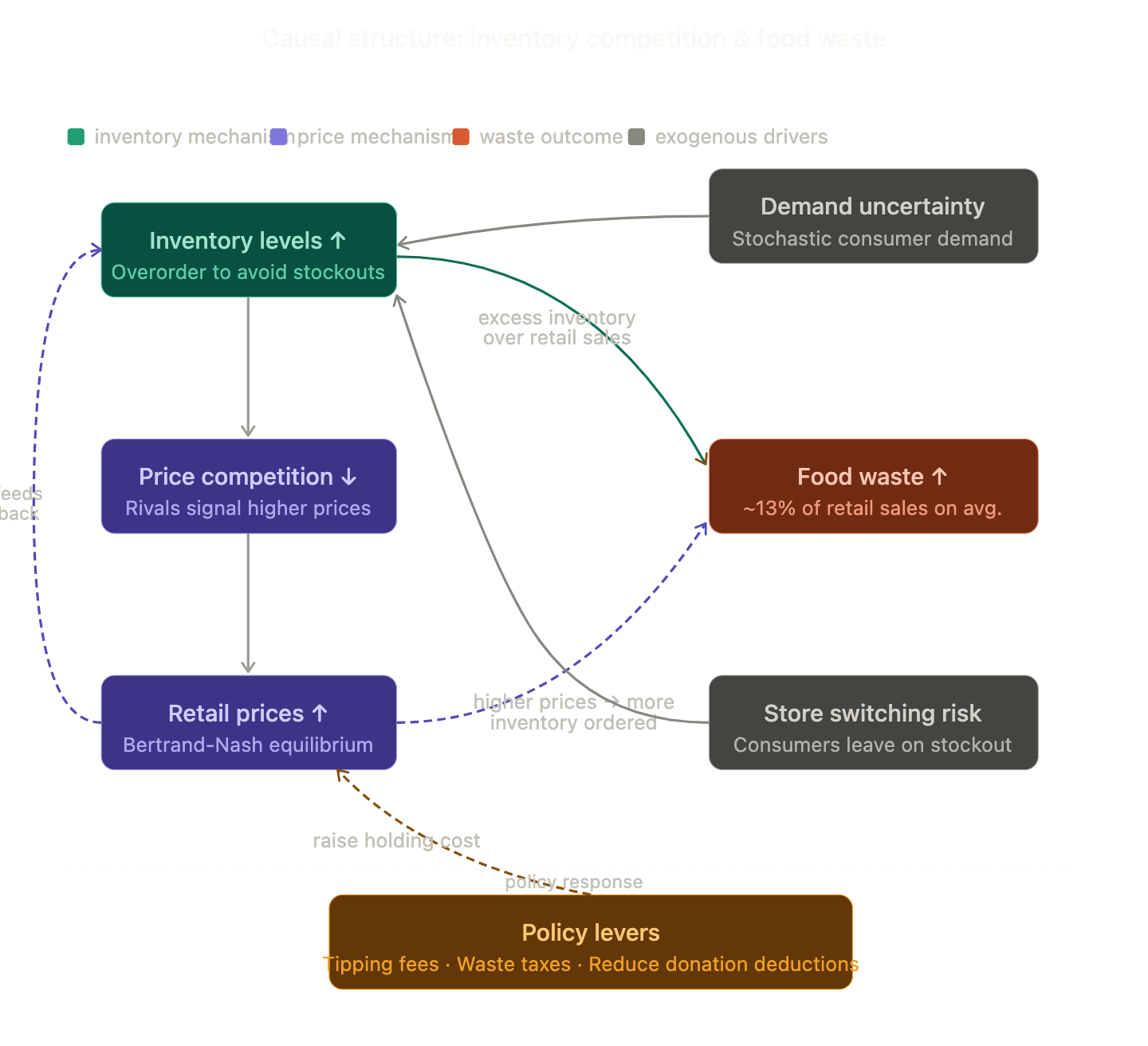
Then I set up 8 inventory questions:
Why do grocery retailers waste so much food?
What is the causal chain from a grocery stockout to food waste?
In a competitive grocery market, how does rivalry between retailers affect how much inventory they hold?
Why do grocery retailers donate excess food to food banks rather than simply ordering less?
What policies would most effectively reduce food waste at the grocery retail level?
In grocery retail, does competing on price or competing on shelf availability have a bigger impact on food waste?
Is demand uncertainty the main reason grocery retailers overorder inventory?
If one grocery retailer stocks its shelves more heavily, what happens to prices and inventory levels at competing stores?
For each, I sent it to the Claude API, with 1 of 3 supporting artifacts; the entire research paper (Long Context), 6 raw chunks from the paper that represent the core ideas (RAG style), or 10 causal relationships from the DAG above (Causal RAG).

I had another LLM call judge the question responses. As expected, the Causal RAG approach performed just as well as the Long Context approach, but used only 2% of the input tokens to get there.
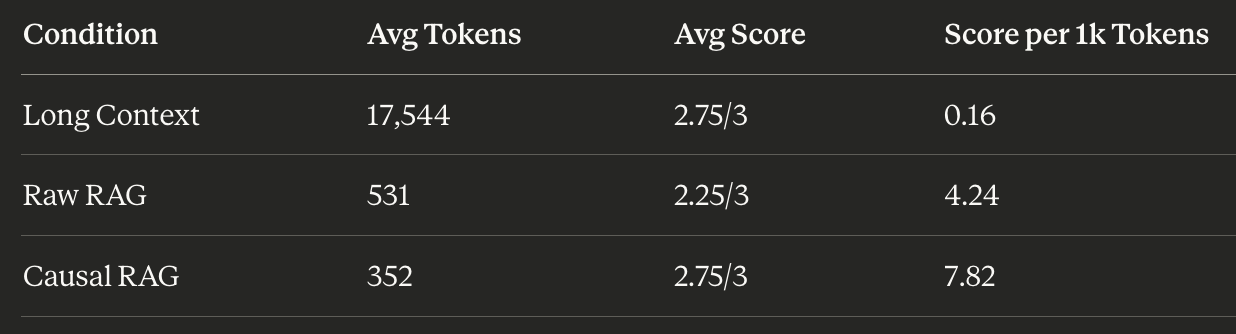
Claude told me that the cost of an input token is ~$3 per million. Across 8 questions, Long Context costs about $0.42 in input tokens. Causal RAG costs about $0.009.
The bigger idea
Claude thinking I’m still with Alex isn’t a memory problem. It’s a signal problem. The right information wasn’t there, or the wrong information crowded it out.
Agents fail the same way. Not because they’re not capable… but because we hand them a firehose when they needed a glass of water.
Now, this isn’t data science. This is simply me thinking quantitatively. It’s loose, I know. But it makes me think there’s opportunity here for companies like Consensus or Semantic Scholar to turn their research knowledge graphs into compressed context for the army of AI Agent on the horizon.
.
Post Script
Dan, I know you are waiting for this so here’s the 2-sentence summary of that research paper: Most people think grocery retailers overstock because demand is unpredictable. But actually, they overstock strategically… holding excess inventory signals rivals to raise prices, making waste a feature of competition, not a failure of forecasting.
I could risk a “no additional context” run; a wildcard option. If I do, I’ll probably get a coherent and ok result. But in many cases (like, with situations involving Frank’s heart), you want a higher threshold.
Combination of Sonnet 4.6 and Opus 4.5
I find llms are particularly bad at time sequences of events like your relationship status. I wonder how your casual rag approach could solve this.